In der dynamischen Welt der Suchmaschinenoptimierung ist die Eindeutigkeit von Inhalten eine der wichtigsten Währungen. Duplicate Content, also identische oder nahezu identische Inhalte, die unter verschiedenen URLs erreichbar sind, stellt für viele Webseitenbetreiber eine erhebliche Herausforderung dar.
Was auf den ersten Blick wie ein technisches Detail wirkt, kann tiefgreifende Auswirkungen auf deine Sichtbarkeit und die Effizienz deiner gesamten SEO-Strategie haben.
Für Google und andere Suchmaschinen ist das Ziel klar: Dem Nutzer soll das relevanteste und einzigartigste Ergebnis präsentiert werden. Wenn das System jedoch auf Duplikate stößt, gerät dieser Prozess ins Stocken. In diesem Leitfaden erfährst du, wie du Duplicate Content identifizierst, strategisch bewertest und technisch löst.
Wenn du dabei SEO-Beratung benötigst, zeigen wir dir auch, wie professionelle SEO-Maßnahmen dabei helfen können, nachhaltige Sichtbarkeit in Suchmaschinen aufzubauen.

Was ist Duplicate Content? Definition und strategische Abgrenzung
Duplicate Content (DC) bezeichnet Textblöcke oder ganze Seiteninhalte, die entweder innerhalb einer Domain oder über verschiedene Domains hinweg mehrfach vorkommen.
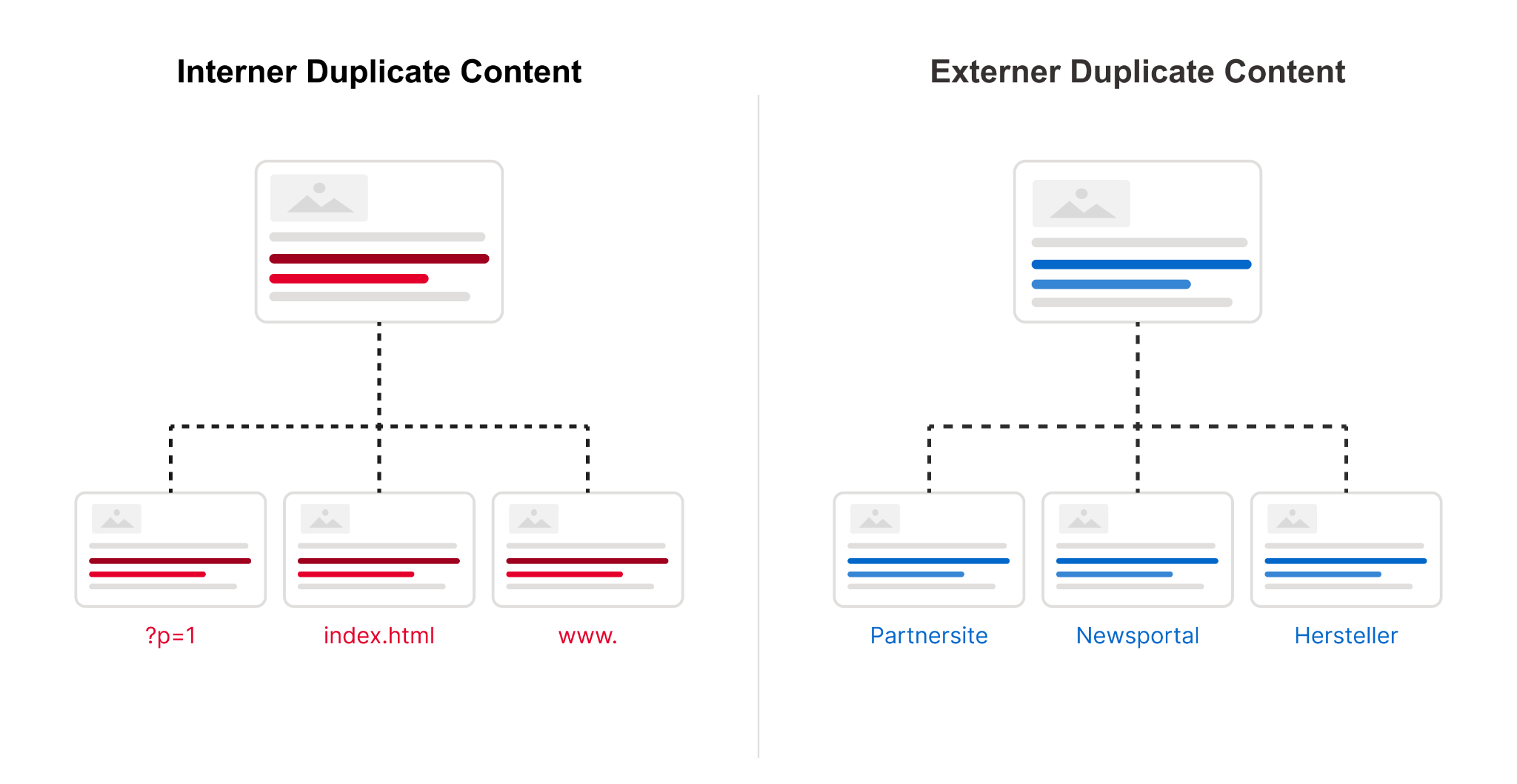
Interner vs. Externer Duplicate Content
- Interner Duplicate Content: Entsteht innerhalb deiner eigenen Website, oft durch technische Konfigurationen (z. B. URL-Parameter, Erreichbarkeit mit/ohne www).
- Externer Duplicate Content: Tritt auf, wenn deine Inhalte auf anderen Domains erscheinen, etwa durch Content-Syndication, Herstellertexte oder Scraping.
Wichtig: Google bevorzugt hierbei nicht zwingend die Version, die zuerst veröffentlicht wurde, sondern diejenige mit den stärksten Autoritätssignalen und der eindeutigsten Ursprungsquelle. Falls du einen drastischen Sichtbarkeitsverlust bemerkst, empfiehlt sich ein professioneller Google Penalty Check.
Die Herausforderung: Near Duplicate Content
Near Duplicate Content beschreibt Inhalte, die sich nur geringfügig unterscheiden. Häufig entsteht dies bei Produktseiten, Kategorieseiten oder rechtlich erforderlichen Standardtexten. Entscheidend ist, dass der einzigartige Mehrwert einer Seite deutlich überwiegt und der wiederkehrende Content nur einen untergeordneten Anteil ausmacht.
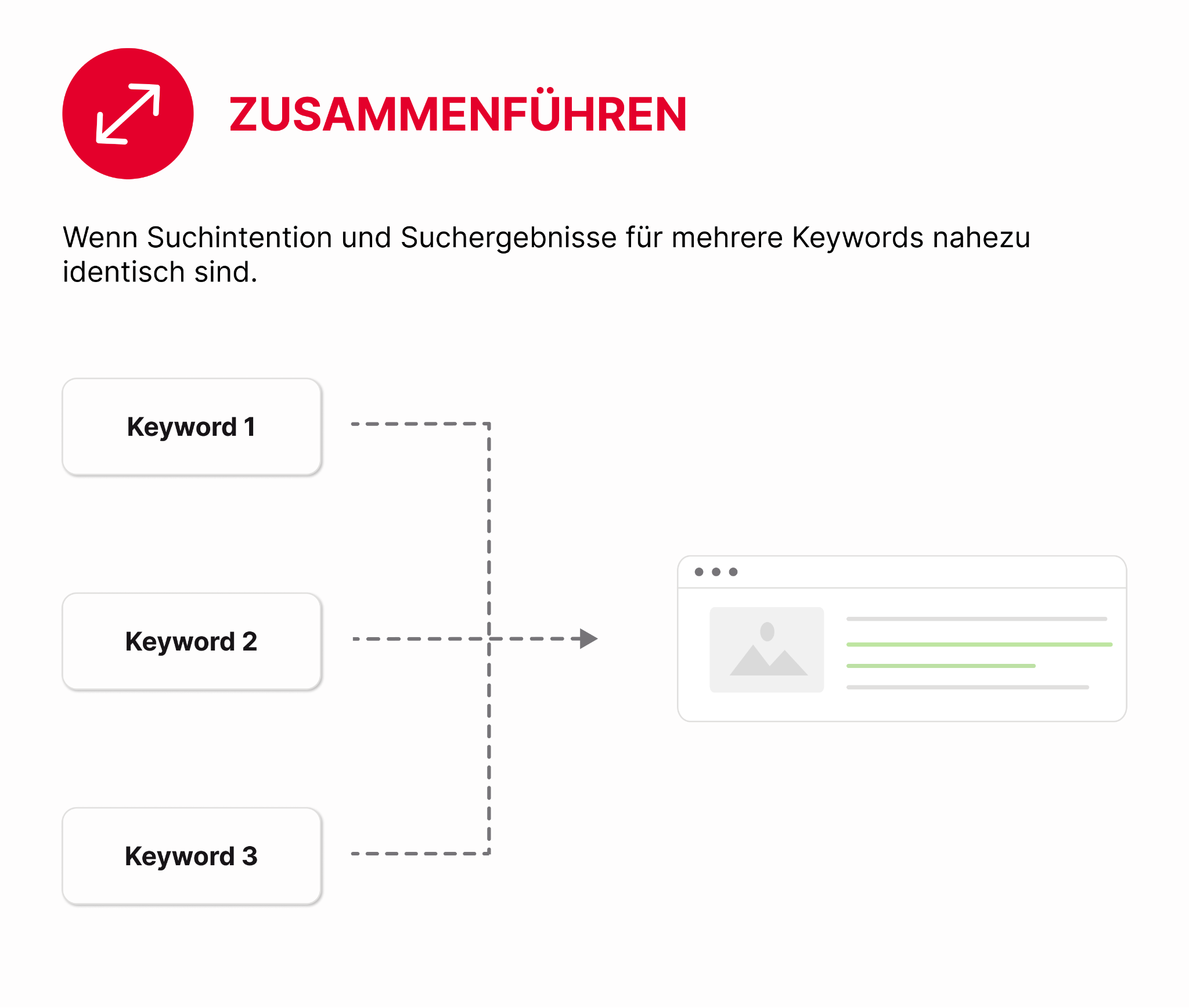
- Zusammenführen (Merge): Wenn Suchintention und Suchergebnisse für mehrere Keywords nahezu identisch sind.
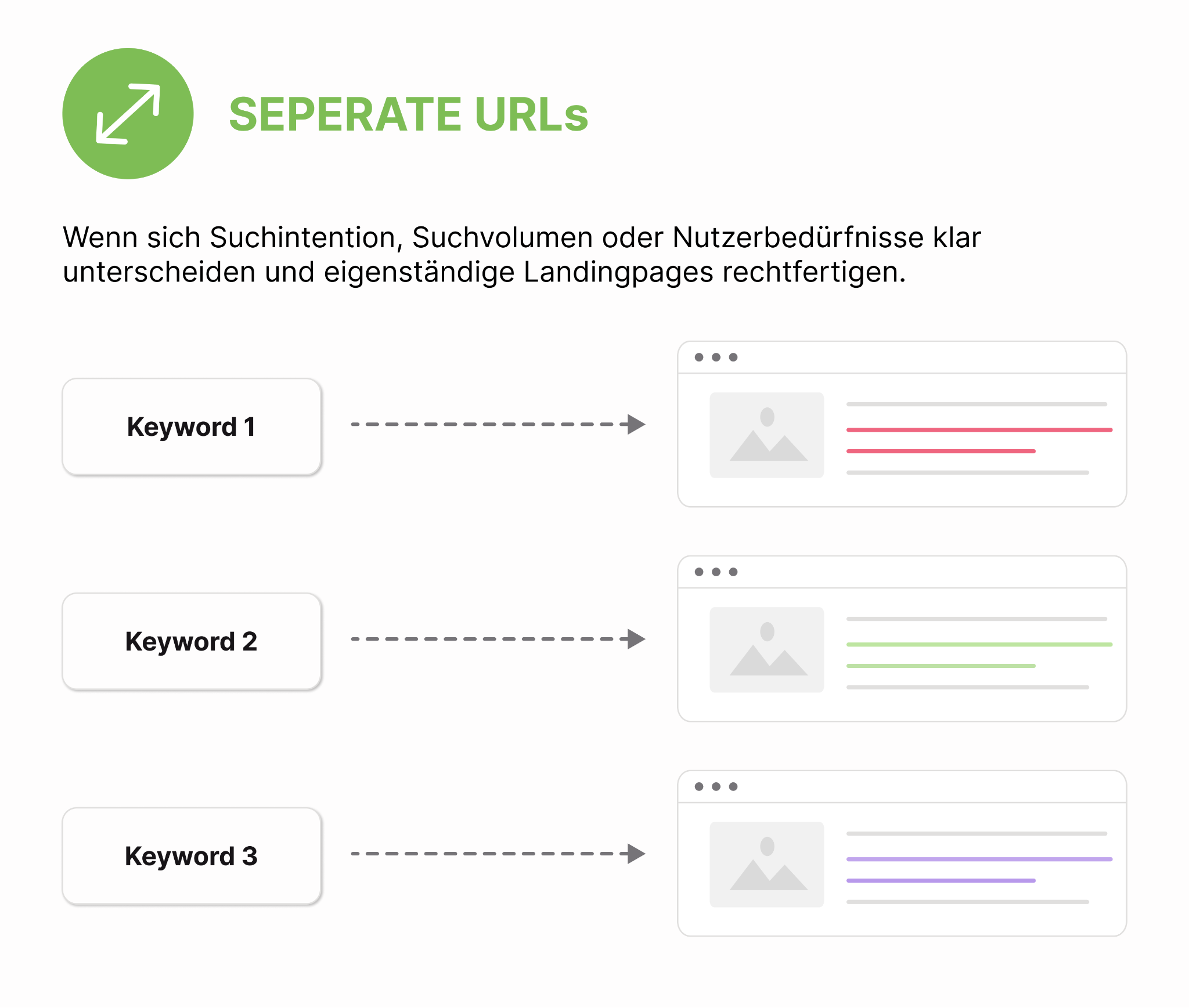
- Separate URLs: Wenn sich Suchintention, Suchvolumen oder Nutzerbedürfnisse klar unterscheiden und eigenständige Landingpages rechtfertigen.
Technische Besonderheiten
Wiederkehrende Pflichtinhalte, beispielsweise Batterie-, Sicherheits- oder Rechtshinweise, sind meist unkritisch. Einige Webseitenbetreiber blenden solche Textbausteine über CSS-Lösungen (z. B. ::before oder ::after) aus, damit sie für Suchmaschinen weniger stark gewichtet werden. Diese Vorgehensweise bewegt sich jedoch in einer Grauzone und sollte mit Vorsicht eingesetzt werden. Nachhaltiger ist es, den einzigartigen Content-Anteil der Seite konsequent auszubauen.
Warum Duplicate Content deine SEO-Performance gefährdet
Entgegen weitverbreiteter Mythen verhängt Google keine manuelle „Penalty" für DC. Die negativen Auswirkungen auf die Performance sind dennoch massiv:
- Belastung des Crawl-Budgets: Jede Website verfügt über ein begrenztes Budget. Wenn der Googlebot hunderte URLs mit identischem Inhalt verarbeiten muss, fehlen diese Ressourcen für wichtige, neue Seiten. Das Ziel ist, Google nur die Seiten indexieren zu lassen, die echten Mehrwert bieten. Eine saubere Sitemap SEO Struktur ist hierfür essenziell.
- Keyword-Kannibalisierung: Mehrere URLs konkurrieren um dasselbe Keyword. Statt einer starken Seite auf Position 1 ranken zwei Seiten z. B. auf den Plätzen 12 und 15.
- Verwässerung der Link-Autorität: Interne und externe Backlinks verteilen ihre Kraft auf verschiedene URL-Varianten, anstatt sich an einem kanonischen Punkt zu bündeln.
Technische Ursachen: Woher die Duplikate kommen
Die Ursachen für Duplicate Content liegen häufig in technischen Gegebenheiten. Vor allem Content-Management-Systeme, Shop-Plattformen und automatisierte URL-Strukturen erzeugen schnell mehrere Versionen derselben Inhalte.
E-Commerce & CMS-Strukturen
Besonders im E-Commerce ist die Gefahr groß:
- Filter-Kombinationen: URLs wie ?color=blue&size=xl erzeugen tausende Varianten ohne neuen Content.
- Variantenprodukte: Wenn sich Produkte nur durch die Farbe unterscheiden, aber der Beschreibungstext identisch bleibt.
- Interne Suche: Indexierte Suchergebnisseiten sind eine klassische DC-Quelle.
Häufig übersehene Duplicate-Content-Fallen
- Staging-Umgebungen: Oft wird vergessen, Test-Server (z. B. dev.domain.de) per Passwortschutz oder Noindex vor Google zu verbergen. Solche Fehler lassen sich durch eine begleitende SEO-Relaunch-Beratung systematisch vermeiden.
- PDF-Dokumente: Bedienungsanleitungen oder Datenblätter, die den exakten Text der Produktseite enthalten, konkurrieren mit der HTML-Version. Abhilfe schaffen ein X-Robots-Tag mit noindex oder ein HTTP-Header-Canonical, das auf die bevorzugte HTML-Seite verweist.
- Trailing Slashes & Protokolle: Fehlende Weiterleitungen von HTTP auf HTTPS oder Inkonsistenzen bei Schrägstrichen am URL-Ende. Zur Identifikation dieser Fehler helfen oft kostenlose SEO-Tools.
Internationalisierung: DC über Ländergrenzen hinweg
Identische Inhalte in derselben Sprache (z. B. DE-DE und DE-AT oder EN-US und EN-GB) können auch im internationalen SEO zu Duplicate Content führen. Besonders problematisch wird es, wenn Inhalte lediglich für verschiedene Länder dupliziert werden, ohne dass relevante Anpassungen erfolgen.
- hreflang-Attribut: Das wichtigste technische Signal für Suchmaschinen. Es zeigt Google, welche Sprach- oder Länderversion für welche Zielgruppe vorgesehen ist. Das hreflang-Attribut löst jedoch nicht automatisch alle Duplicate-Content-Probleme.
- Regionale Anpassung: Auch bei korrekt implementiertem hreflang sollten Inhalte möglichst an die jeweilige Zielregion angepasst werden. Dazu gehören lokale Begriffe (z. B. „Jänner" statt „Januar"), Währungen, Maßeinheiten, Lieferinformationen, rechtliche Hinweise oder regionale Besonderheiten.
Vorsicht bei Content-Klonen: Wer beispielsweise einen englischsprachigen Shop für Großbritannien, die USA, Kanada, Australien und weitere Märkte nahezu identisch kopiert, schafft trotz hreflang ein großes Maß an inhaltlicher Überschneidung. Je stärker sich die Inhalte unterscheiden und auf die Bedürfnisse des jeweiligen Marktes eingehen, desto einfacher kann Google die einzelnen Versionen als eigenständige und relevante Seiten bewerten.
Analyse mit der Google Search Console (GSC)
Die GSC ist das wichtigste Diagnose-Tool. Achte im Bericht „Seitenindexierung" auf folgende Meldungen:
- „Duplikat – vom Nutzer nicht als kanonisch festgelegt": Google hat Duplikate gefunden, aber du hast keinen Canonical Tag gesetzt. Google wählt nun selbst eine Version aus.
- „Google hat eine andere kanonische Seite als der Nutzer bestimmt": Dein gesetzter Canonical Tag wurde ignoriert. Prüfe in diesem Fall unbedingt deine SEO Meta Tags auf Konsistenz.
Praxis-Tipp: Prüfe deine interne Verlinkung. Wenn du per Canonical auf URL A verweist, aber intern fast ausschließlich auf URL B verlinkst, erzeugst du widersprüchliche Signale.
Lösungswege: Korrekte Kanonisierung und Redirects
Um Suchmaschinen die bevorzugte Version einer Seite eindeutig zu signalisieren, kommen in der Praxis vor allem Canonical Tags und 301-Weiterleitungen zum Einsatz.
Der Canonical Tag vs. 301-Weiterleitung
- 301-Redirect: Die beste Lösung, wenn eine URL-Variante dauerhaft nicht mehr existieren soll. Die Linkkraft wird fast vollständig übertragen.
- Canonical Tag: Ideal, wenn mehrere URLs aus technischen Gründen erreichbar bleiben müssen, aber nur eine Version ranken soll.
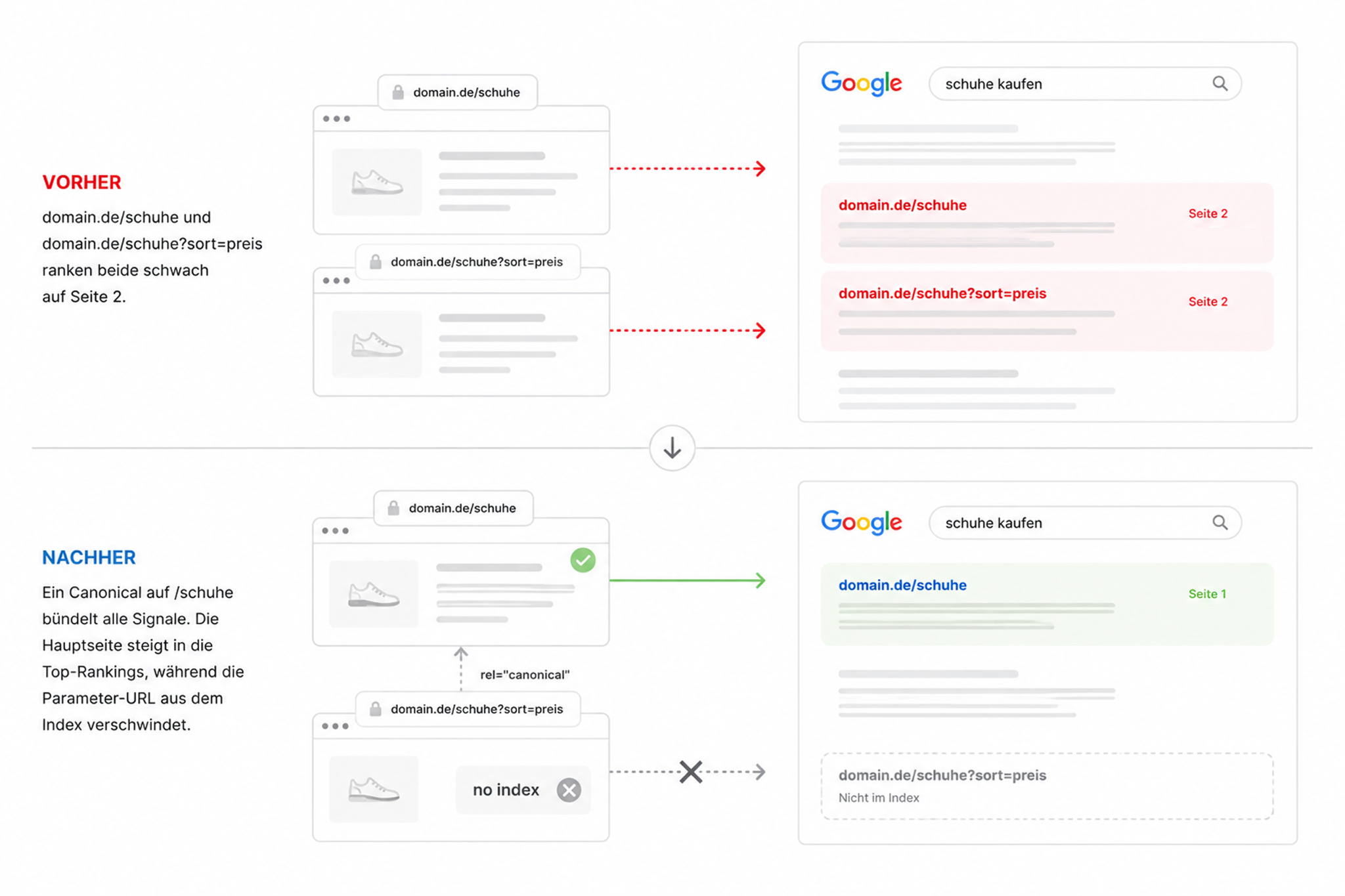
Vorher-Nachher-Szenario
Vorher: domain.de/schuhe und domain.de/schuhe?sort=preis ranken beide schwach auf Seite 2.
Nachher: Ein Canonical auf /schuhe bündelt alle Signale. Die Hauptseite steigt in die Top-Rankings, während die Parameter-URL aus dem Index verschwindet.
Monitoring: Duplicate Content dauerhaft verhindern
Ein einmaliger Audit reicht nicht aus. Professionelles Management erfordert:
- Regelmäßige Crawls: Nutze SEO-Tools wie Screaming Frog, um Duplicate Content und Near Duplicate Content kontinuierlich zu überwachen. Über die integrierte Ähnlichkeitsanalyse lassen sich Seiten identifizieren, die sich inhaltlich stark überschneiden und potenziell um dieselben Rankings konkurrieren.
- Logfile-Analyse: Prüfe, wie häufig Suchmaschinen Duplikate oder unwichtige URL-Varianten crawlen. Besonders bei großen Websites können Parameter-URLs oder Facettennavigationen unnötige Crawling-Ressourcen binden.
- Google Search Console überwachen: Kontrolliere regelmäßig die Indexierungsberichte. Hinweise wie „Alternative Seite mit richtigem Canonical-Tag", „Duplikat, vom Nutzer nicht als Canonical festgelegt" oder „Gecrawlt, zurzeit nicht indexiert" können auf Duplicate-Content-Probleme oder Schwierigkeiten bei der URL-Konsolidierung hinweisen.
Fazit: Proaktives Management für nachhaltige Sichtbarkeit
Duplicate Content ist kein statisches Problem, sondern eine strategische Aufgabe. Durch saubere technische Direktiven und den Fokus auf „Information Gain" sicherst du dir die Spitzenpositionen in den Suchergebnissen von morgen.
Möchtest du deine Website auf technische Fehler prüfen lassen? Tritt direkt mit uns in Kontakt. Wir unterstützen dich dabei, deine Daten in messbare Erfolge zu verwandeln.
FAQ: Alles zu Duplicate Content
Was ist Duplicate Content einfach erklärt?
Duplicate Content bezeichnet identische oder sehr ähnliche Inhalte, die unter mehr als einer URL im Internet erreichbar sind. Dies verwirrt Suchmaschinen bei der Entscheidung, welche Version ranken soll.
Gibt es eine Google Penalty für Duplicate Content?
Nein, in der Regel gibt es keine direkte Abstrafung. Google filtert Duplikate jedoch aus den Suchergebnissen heraus, was zu Sichtbarkeitsverlusten führt.
Wie finde ich Duplicate Content auf meiner Website?
Du kannst die Google Search Console verwenden oder spezialisierte Tools wie Siteliner, Copyscape oder SEO-Crawler wie den Screaming Frog einsetzen.
Was ist ein Canonical Tag?
Ein Canonical Tag (rel="canonical") ist ein HTML-Element, das Suchmaschinen mitteilt, welche URL die bevorzugte „Hauptversion" einer Seite ist.
Ist Duplicate Content immer schlecht?
Technisch gesehen ja, da er Crawl-Ressourcen verschwendet. Für Nutzer können Duplikate (z. B. eine Druckansicht) sinnvoll sein, müssen aber technisch für Bots markiert werden.
Verursachen URL-Parameter Duplicate Content?
Ja, wenn Parameter (z. B. für Sortierungen) den Seiteninhalt nicht wesentlich verändern, entstehen für Google viele neue URLs mit dem gleichen Content.
Wie wirkt sich Duplicate Content auf das Crawl-Budget aus?
Suchmaschinen verbringen Zeit damit, Duplikate zu crawlen, anstatt neue oder wichtige Inhalte zu entdecken. Dies reduziert die Effizienz der Indexierung.
Hilft das Löschen von Duplikaten beim Ranking?
Ja, die Konsolidierung von Inhalten auf einer starken URL (z. B. via 301-Redirect) bündelt die Link-Autorität und verbessert oft das Ranking der verbleibenden Seite.
Ist Content in verschiedenen Sprachen Duplicate Content?
Nein. Übersetzter Content gilt als einzigartig. Für regionale Varianten der gleichen Sprache (z. B. DE-DE und DE-AT) sollte jedoch das hreflang-Attribut verwendet werden.
Kann KI-generierter Text als Duplicate Content gewertet werden?
Ja, wenn die KI Inhalte erstellt, die bereits massenhaft in ähnlicher Form im Netz existieren, erkennt Google den mangelnden „Information Gain" und stuft den Content als minderwertig oder redundant ein.